开源11天,马斯克再发Grok-1.5!128K代码击败GPT-4
发布时间:2024-03-29 11:40:00 来自:网易科技

新智元报道
编辑:桃子好困
马斯克「搞笑」模型刚刚升级到 Grok-1.5,推理性能暴涨,支持 128k 长上下文。最重要的是,Grok-1.5 的数学和代码能力大幅提升。
Grok-1 官宣开源不过半月,新升级的 Grok-1.5 出炉了。
刚刚,马斯克 xAI 官宣,128K 上下文 Grok-1.5,推理能力大幅提升。
并且,很快就会上线。
11 天前,Grok-1 模型的权重和架构开源,展示了 Xai 在去年 11 月之前取得的进展。
Grok-1 有 3140 亿参数,是 Llama 2 的 4 倍大,而且采用的是 MoE 架构,8 个专家中 2 个是活跃专家。
Xai 介绍,也就是从那时起,团队改进了最新模型 Grok-1.5 的推理和解决问题的能力。

OpenAI 前开发者关系负责人表示,从 xAI 重大发布的时间可以看出他们前进的步伐和紧迫感。令人振奋!

128K 上下文,Grok-1.5 数学推理能力暴涨
根据官方介绍,Grok-1.5 改进了推理能力,上下文长度为 128K。

Grok-1.5 最显著的改进之一是,它在编码和数学相关任务中的表现。
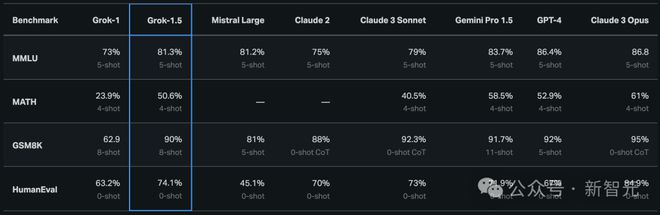
在测试中,Grok-1.5 在数学基准上取得 50.6% 的得分,在 GSM8K 基准上获得了 90%,这两个数学基准涵盖了从小学到高中的各种竞赛问题。
此外,在评估代码生成和解决问题能力的 HumanEval 基准测试中,Grok-1.5 获得了 74.1% 的高分。
从下图中,与 Grok-1 相比,可以看出 Grok-1.5 在数学方面的能力得到大幅提升,GSM8K 上从 62.9% 改进到 90,MATH 上从 23.9% 提升到 50.6%。
128K 长语境理解,扩增 16 倍
Grok-1.5 另一全新特点是,能够在其上下文窗口内处理高达 128K token 的文本。
这使 Grok 的内存容量,增加到以前上下文长度的 16 倍,从而使它能够利用更长的文档中的信息。
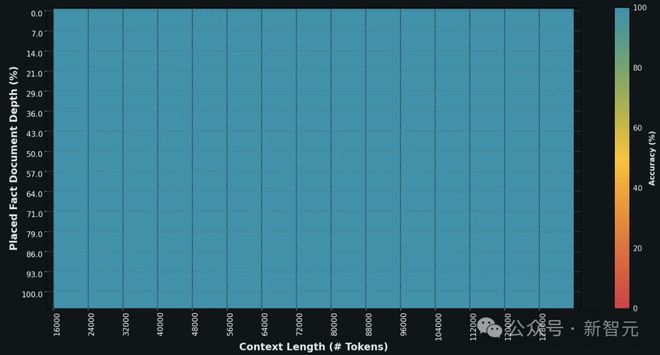
此外,新模型还可以处理更长和更复杂的提示,同时在其上下文窗口扩展时仍保持其指令跟随能力。
在 Needle In A Haystack(NIAH)评估中,Grok-1.5 展示了强大的检索能力,可检索长度达 128K 字节的上下文中的嵌入文本,并取得了完美的检索结果。
Grok-1.5 基础设施
Grok-1.5 构建在基于 JAX、Rust 和 Kubernetes 的定制分布式训练框架之上。
这个训练堆栈可以让 xAI 团队能够以最少的投入,大规模构建创意,以及训练新的架构。
在大型计算群集上进行训练 LLM 的一个主要挑战是,最大限度地提高训练任务的可靠性和正常运行时间。
xAI 定制的训练编排器,可确保自动检测有问题的节点,并将其从训练任务剔除。
与此同时,他们还优化了检查点、数据加载和训练任务的重启,以最大限度地减少发生故障时的停机时间。
xAI 表示,Grok-1.5 将很快提供给早期测试者,以帮助改进模型。
博客还预告了 Grok-1.5 将在未来几天里推出几个新功能。
最后,xAI 还是一如既往地 po 出了招募信息。

参考资料: